So far, the architecture and the components of a neural network have been discussed in the previous sections. After designing
the network architecture, the next task is to train the network with the training data. To train the network, the data will
be given as an input to the network. Then the loss function will be calculated from the predicted network's output and the desired output.\par
Consider a n-dimensional training sample vector, $\mathbf{x}=[x_1,x_2,x_3......x_n]^T$, where $x_1,x_2,x_3,...,x_n$ are the training pixels (scalar values).
The predicted vector of the network is $\mathbf{\hat{x}}=[\hat{x}_1,\hat{x}_2,\hat{x}_3......\hat{x}_n]^T$, and the desired output vector is $\mathbf{d}=[d_1,d_2,d_3......d_n]^T$.\par
The predicted vector $\mathbf{\hat{x}}$ can be written as: $$ \mathbf{\hat{x}}=f(\mathbf{x},\mathbf{w},b), $$ Where $\mathbf{w}, b$ are the parameters,
that the network or model is supposed to learn and, where $f(.)$ is the activation function.
So we can write the loss function (also called as cost function) as a function of weights and the bias.
\begin{equation}
J(\mathbf{w},b)=\frac{1}{n}\sum_{i=1}^{n}\big({ x_i-\hat{x_i} }\big)^2
\end{equation}
This cost function is called Mean-Squared-Error (MSE) cost function. In training, the
key task is to minimize this cost function by adjusting the weights and the bias connections.
Gradient descent algorithm
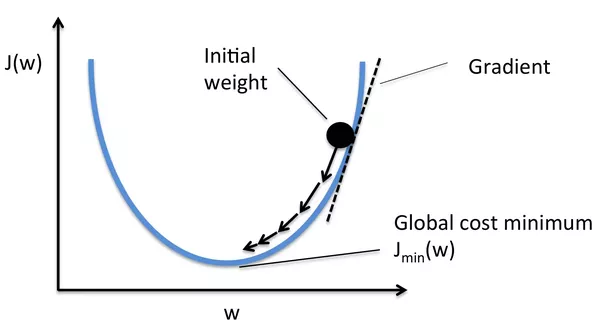
The gradient descent algorithm is a very efficient way to find the optimum values of the weights for which the cost function can be minimized.
Figure : Gradient descent algorithm to optimize the cost function. The goal is to find the optimum cost function $J(W)$ by varying the weights $W$.
In this algorithm, the values of weights are randomly initialized,
as shown in Figure \ref{sgd}, and the cost is calculated according to the randomly assigned weights.
To decrease the cost or to find the minimum of the cost function, the weights are updated by taking multiple
steps in the negative gradient direction. The weight update rule is as follows:
\begin{equation}
\boxed{
\mathbf{w}^{k+1}=\mathbf{w}^{k}-\alpha\frac{\partial J(\mathbf{w})}{\partial \mathbf{w}}
}
\end{equation}
Where $\mathbf{w}^{k}$ is the previous weight value, $\mathbf{w}^{k+1}$ is the updated weight value
and $\alpha$ is called the step size or learning rate. \par
The learning rate $\alpha$ is a very vital hyperparameter which needs to be set manually. The learning rate
should be chosen very carefully, if $\alpha$ is too small, it ensures that it will reach the minimum point of
the function, but it may take very long time to reach the bottom of the cost function. On the other hand,
if $\alpha$ is large, then it may deviate from the correct path of going to the bottom of the function, it may fail to converge. \par
In the gradient descent algorithm we calculate the gradient, i.e., we take the partial derivatives of the cost
function with respect to the variables of the cost function. The gradient descent updates the hyperparameters after
looking at all the training samples. This process makes this algorithm computationally expensive and very slow. One more problem in the
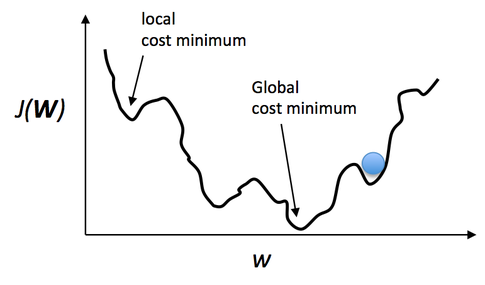
gradient descent algorithm is that, if the cost function is non-convex, as shown in Figure \ref{non_convex}. If the cost function has
many hills and valleys, or irregular surface, then this algorithm may find local minimum, instead of finding the global minimum.
Figure : An example of non-convex cost function. It may be very challenging to find the global
minimum point of a non-convex cost function for the gradient descent algorithm.
As a solution of the above mentioned problems, there is a modification in the
gradient descent algorithm, it is called Stochastic Gradient Descent (SGD). In SGD, the
gradient is computed and the weight is updated from every single training sample. This process
in continued for each and every training samples. It does not need to go through all the training
samples to do one single update in weights like the gradient descent. As a consequence, the SGD is
faster than the gradient descent. Since we calculate the gradient for every single training sample,
the gradient gets very noisy and there are higher fluctuations.\par
There is another variation, it is called Mini Batch Gradient Descent (MB-GD). In this method,
the training dataset is randomly subdivided into batches, e.g., 10 or 20 or more training samples are grouped together.
Then the batches are passed through the network to update the weights. This modified version is more popular than above
discussed other two versions. It is less noisy than the SGD and additionally faster compared to the gradient descent.
Backpropagation algorithm
Among different approaches \cite{LeCun} to train the neural network, the gradient based learning approach is considered as a successful approach. If we recall the Equation \ref{sgd_eqn}, it shows that, computing gradient is a fundamental task to update or adjust the weights.
$$\mathbf{w}^{k+1}=\mathbf{w}^{k}-\alpha\boxed{\frac{\partial J_i(\mathbf{w},b)}{\partial \mathbf{w}}}$$
Backpropagation is an efficient process of calculating the gradients of the cost function with respect to the weights of the network to update the weights.
There are two basic steps in the backpropagation algorithm:
Forward propagation
Backward propagation
This backward propagation step can be further sub-divided into two steps:
Backpropagation to the output layer
Backpropagation to the hidden layer
Forward propagation
After setting the network architecture, consider a $n$-dimensional training sample vector and a $n$-dimensional desired output vector.
$$\{ (x_{i},d_{i})\}, i=1,2,3,4,........,n,$$
where $x_{i}$ is the input vector and $d_{i}$ is the desired output vector.
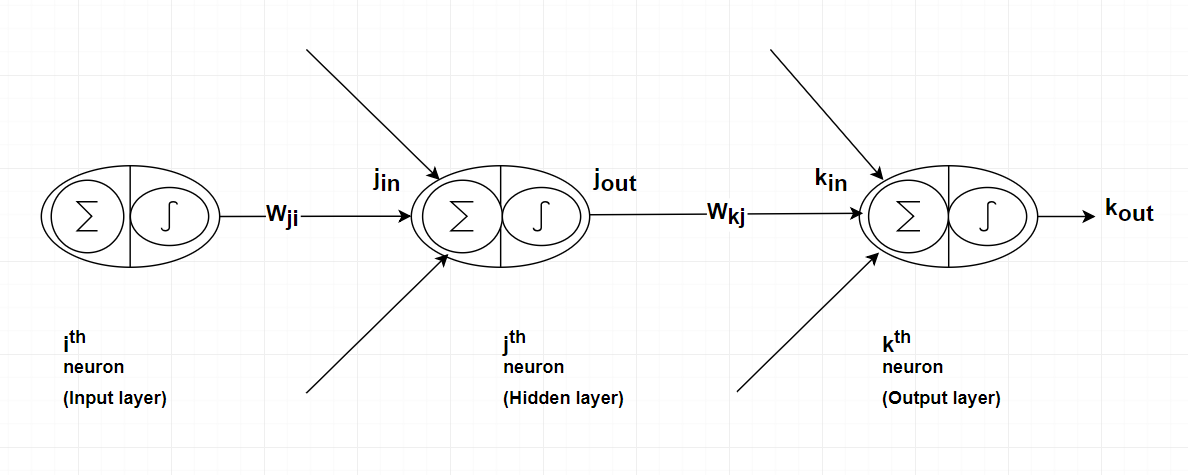
The training data will be given as an input vector to the network. Input data points will be passed through the hidden layers, where each hidden neuron takes the weighted sum of the the input points and that sum will be passed through the nonlinear activation function (e.g. Sigmoid, ReLU, etc). The output of the hidden layer will be the input for the output layer, if we consider a $2$-layer network like Figure \ref{neural_network_architectue}. The output layer neurons will process the arrived input data and produce the output of the network.
If the network output vector is $\mathbf{y}=[y_{1},y_{2},y_{3},....,y_{n}]$, then the error can be calculated in the output layer, denoted by $E$, as follows:
\begin{equation}
E=\frac{1}{n}\sum_{i=1}^{n}\big({ d_{i}-{y_{i}} }\big)^2
\label{error_eqn}
\end{equation}
Now the objective is to calculate the derivatives of the error with respect to the hidden layer weights and output layer weights.
Backward propagation
This step is called as the error correction step. The error correction step takes place after passing a training input sample through the network i.e., after completing the forward propagation.
Each neuron in the output layer produces an output result, which will be compared with the desired output. The difference between desired and produced output is the error, which is calculated for all the output neurons. Then the weights are adjusted for all the weight connections between the output layer and previous hidden layer. The error value is calculated for all the neurons in hidden layer, and again all the weight connections between input layer and hidden layer are adjusted. If there are more hidden layers, then in the same way all the weights will be adjusted. Since the error is propagating from the output layer to the input layer, hence it is called backpropagation.
Figure : ignals from the input layer to the output layer of a two layer network.
Consider a two-layer network, where the error will be propagated from the output layer to the hidden layer. To adjust weights between output layer and hidden layer, we need to find the derivatives of the error function (see Equation \ref{error_eqn}) with respect to the weights.
This backpropagation to the output layer, and the hidden layer will be discussed with the help of Figure \ref{backprop_figure}.
Backpropagation to the output layer
Consider a neuron in hidden layer, $j^{th}$ neuron, and a neuron in output layer, $k^{th}$ neuron, and the connected weight between them is denoted by $w_{kj}$.
The error function does not explicitly depend on the output layer weight $w_{kj}$. It depends on the output of the $k^{th}$ neuron $k_{out}$.
$k_{out}$ is a function of input of the $k^{th}$ neuron $k_{in}$,
$k_{in}$ is a function of the output layer weight $w_{kj}$.
So the derivatives can be calculated by using the calculus chain rule.
The derivative of the error function $E$ w.r.t. the $w_{kj}$ weight as follows:
\begin{equation}
\boxed{
\frac{\partial E}{\partial w_{kj}}=\frac{\partial E}{\partial k_{out}}*\frac{\partial k_{out}}{\partial k_{in}}*\frac{\partial k_{in}}{\partial w_{kj}}
}
\label{backprop_output_formula}
\end{equation}
Backpropagation to the hidden layer
The weight between the input layer $i^{th}$ neuron and the hidden layer $j^{th}$ neuron is denoted by $w_{ji}$. The derivative of the error function $E$ w.r.t. the $w_{ji}$ can be calculated by:
\begin{equation}
\frac{\partial E}{\partial w_{ji}}=\frac{\partial E}{\partial j_{out}}*\frac{\partial j_{out}}{\partial j_{in}}*\frac{\partial j_{in}}{\partial w_{ji}}
\label{backprop_hidden_formula}
\end{equation}
The error is entering to the hidden layer from output layer through the first term of the Equation \ref{backprop_hidden_formula}. Since $k_{in}$ also depends on the output of the $j^{th}$ neuron $j_{out}$, the term $\frac{\partial E}{\partial j_{out}}$ can be elaborated as follows:
\begin{equation}
\frac{\partial E}{\partial j_{out}}=\frac{\partial E}{\partial k_{out}}*\frac{\partial k_{out}}{\partial k_{in}}*\frac{\partial k_{in}}{\partial j_{out}}
\label{backprop_hidden_formula_2}
\end{equation}
By substituting the value from Equation \ref{backprop_hidden_formula_2} to Equation \ref{backprop_hidden_formula}, the gradient of the hidden layer neuron is computed.
\begin{equation}
\boxed{
\frac{\partial E}{\partial w_{ji}}=\frac{\partial E}{\partial k_{out}}*\frac{\partial k_{out}}{\partial k_{in}}*\frac{\partial k_{in}}{\partial j_{out}}*\frac{\partial j_{out}}{\partial j_{in}}*\frac{\partial j_{in}}{\partial w_{ji}}
}
\label{backprop_hidden_formula_final}
\end{equation}
After computing all the gradients in the similar way, the final step is to update the parameters using the gradient descent rule as shown in Equation \ref{sgd_eqn}.
For batch methods, the parameters will be updated after passing all the training samples of a single batch. In that case, the derivative of the error function will be obtained by repeating the above explained forward and backward pass for every single sample and then summing up over all the samples of a batch.